SIMD Optimized LAME Encoder
This page provides Intel/PowerPC/ARM optimized version (using SSE/AltiVec/NEON) of LAME MP3 encoder.
What is it?
LAME is a free, open-sourced mp3 encoder. It is said that LAME offers the best quality among all mp3 encoders.
This page provides LAME binaries and patches optimized for ARM, Intel and PowerPC G4/G5 processor. This version is faster than the original version by utilizing NEON, SSE or AltiVec(aka Velocity Engine, VMX) in those processors. Note that the binary package distributed here only contains the encoder executable and does not contain libmp3lame library.
These binaries sometimes produce a bit different encoding result compared to the reference one. This is due to the difference of the internal precision of floating-point representation between the vector FPU and the scalar FPU, and/or because floating point operations aren't commutative. Basically this should not affect the perceived quality, but if you worry about it try to invert the output waveform and mix with the reference one using the waveform editor like Audacity.
Changes
- Vectorization
- Vectorized FFT routine
- Vectorized MDCT routine
- Vectorized psychoacoustic analysis routine
- Vectorized quantization routine
- Vectorized noise calculation routine
- Vectorized huffman coding routine
- Vectorized replaygain calculation routine
- Algorithm change (for PowerPC only)
- x3/4 calculation with square-root estimation and Newton-Rhapson refinement
- Log(x) calculation with approximate polynomial
- Quantization using the approximate polynomial
Performance
This version is about 85-105%/80-95% faster than the reference on PowerPC G4/G5 when using 3.98b8 (graph).
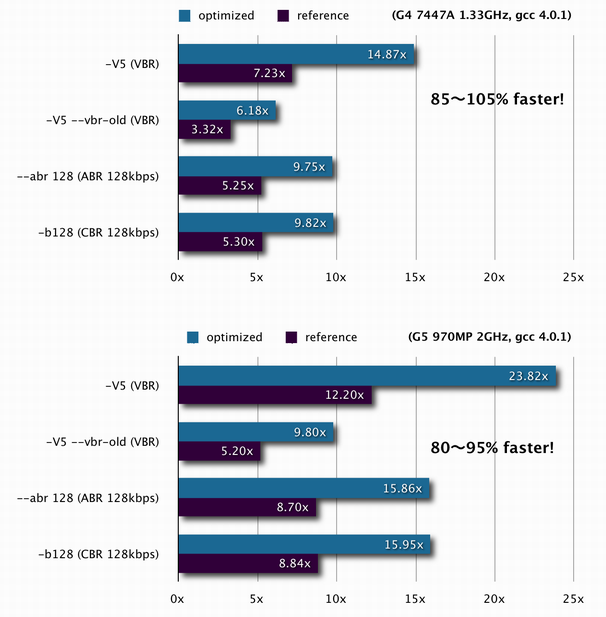{kind=link}
For intel processors, the official version already includes some SSE/MMX optimizations. In addition to this, some extra optimizations are applied in the version 3.99 distributed here (see the graph below).
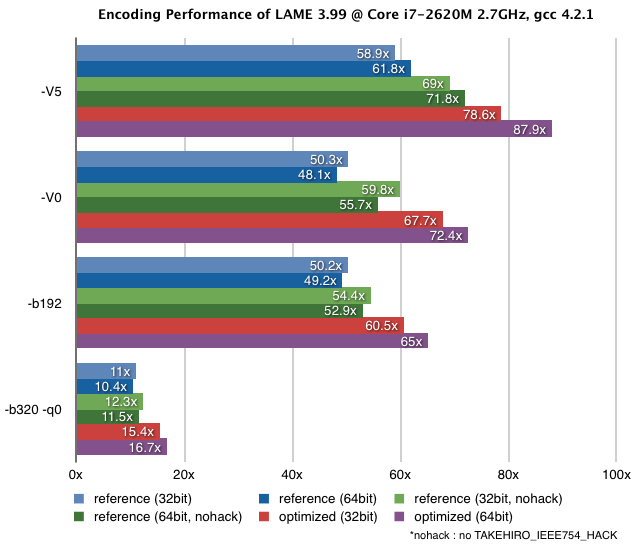
LAME 3.100 (updated on 2023/4/18)
- Executable for Mac OS X Compiled with clang (for x86/arm64) and gcc 4.2.1 (for PPC). Includes a universal binary for all machines. The optimum one is chosen automatically.
- Executable for Windows Compiled with gcc-5.4/MinGW. Includes executable for both 64-bit and 32-bit.
- source diffs (x86)
- Optimized routines are written for the gcc inline assembler, so use gcc (or clang) to compile the patched sources.
- SSE2 support is the minimum requirement for this patch.
- In case SSE3 is enabled in the compiler (with -msse3), SSE3 instructions are used.
- In case SSE4.1 is enabled in the compiler (with -msse4.1), SSE4.1 instructions are used.
- It is highly recommended to enable SSE floating-point math (-msse2 -mfpmath=sse) on 32-bit environments (it is enabled by default on Apple's gcc).
- source diffs (PPC)
- Define ALTIVEC and ALTIVEC_970 macro to build an AltiVec-enabled binary for G5.
- Define ALTIVEC macro to build an AltiVec-enabled binary for G4.
- Define PPC_FRSQRTE macro to build a binary for G3.
- source diffs (ARM)
- Clang or gcc can be used for compiling, but since gcc generates ***very*** inefficient code, it is strongly recommended to use clang compiler.
- This optimization targets AArch64 (ARM64) machines, but it also works on 32-bit (ARMv7) machines. For 32-bit target,
-mfpu=neonswitch is mandatory to enable support for NEON instructions. - For 32-bit target,
-mfpu=neon-vfpv4switch optionally enables FMA (Fused Multiply-Add) instructions.
LAME 3.99.5 (updated on 2012/2/29)
- gcc 4.2 compiled binary for Mac OS X Compiled with gcc 4.2.1. Includes a universal binary for all machines. The optimum one is chosen automatically. Now intel 64-bit binary is included because it has become faster than the 32-bit version thanks to the optimizations
- gcc 4.6/MinGW compiled binary for Windows 64-bit version is not verified to work.
- source diffs (x86)
- Optimized routines are written for the gcc inline assembler, so use gcc (or clang) to compile the patched sources.
- SSE2 support is the minimum requirement for this patch.
- In case SSE3 is enabled in the compiler (with -msse3), SSE3 instructions are used.
- In case SSE4.1 is enabled in the compiler (with -msse4.1), SSE4.1 instructions are used.
- It is highly recommended to enable SSE floating-point math (-msse2 -mfpmath=sse) on 32-bit environments (it is enabled by default on Apple's gcc).
- Patch updated on 2015/10/3, thanks to Robert Kausch for pointing out the issue with recent gccs.
- source diffs (PPC)
- Define ALTIVEC and ALTIVEC_970 macro to build an AltiVec-enabled binary for G5.
- Define ALTIVEC macro to build an AltiVec-enabled binary for G4.
- Define PPC_FRSQRTE macro to build a binary for G3.
LAME 3.98.4 (updated on 2010/3/23)
- gcc4.2 compiled binary for Mac OS X Compiled with gcc 4.2.1. Includes a universal binary for all machines. The optimum one is chosen automatically.
- source diffs
- Define ALTIVEC and ALTIVEC_970 macro to build an AltiVec-enabled binary for G5.
- Define ALTIVEC macro to build an AltiVec-enabled binary for G4.
- Define PPC_FRSQRTE macro to build a binary for G3.
This page is link free.
If you have any comment with this page, please contact me.