最終更新日: 4/18/2023
SIMD Optimized LAME Encoder
このページでは、AltiVec/SSE/NEONを使ってPowerPC/Intel/ARM向けに最適化したLAME (バイナリ/パッチ) を配布しています。
これはなに?
LAMEはオープンソースの高品質なmp3エンコーダです。数あるmp3エンコーダの中で最も品質が良いとされています。
ここにあるのはARM/Intel/G3/G4/G5プロセッサ向けに最適化を行ったLAMEで、公式に配布されているソースコードをコンパイルしたものより速くなっています。なお、lameのフロントエンドのみでライブラリ類は入っていません。
音源によっては非最適化版とは微妙にエンコード結果が異なることがありますが、これは主にAltiVecのVFPUと通常のFPUの内部演算精度の違いやアルゴリズムの変更等によるものです。音質に影響することはまず無いと思いますが、心配な人は波形編集ツール(Audacity等)で逆相足し合わせをしてみてください。
主な変更点
- ベクトル化
- FFTルーチンをベクトル化
- MDCTルーチンをベクトル化
- 心理音響解析ルーチンをベクトル化
- 量子化ルーチンをベクトル化
- 量子化ノイズ計算ルーチンをベクトル化
- ハフマン符号化のためのビットカウントルーチンをベクトル化
- replaygain計算ルーチンをベクトル化
- アルゴリズムの変更 (PowerPCのみ)
- x3/4の計算に平方根近似+ニュートン法を使用 (PPCのみ)
- Log(x)の計算に近似多項式を使用 (オリジナルのテーブル引き+線形補間より精度は良い)
- 量子化の丸めに近似多項式を使用
パフォーマンス
現在のところ、リファレンスのバイナリと比較してG4において85〜105%程度、G5において80〜95%程度、高速化を達成しています(3.98b8, グラフ)。
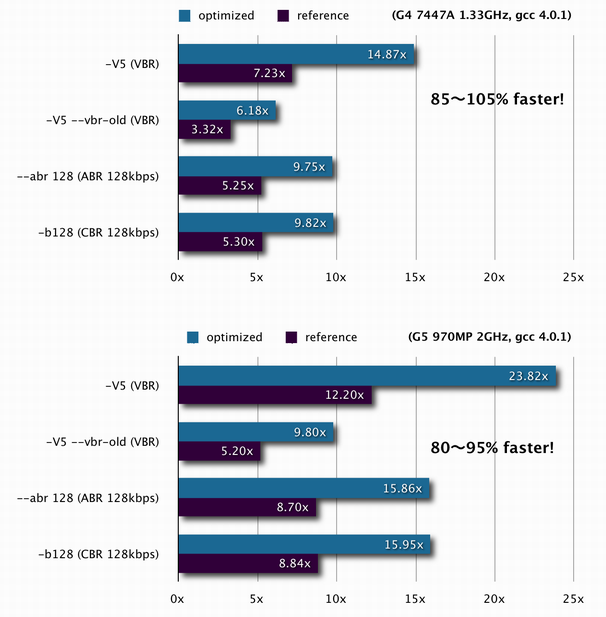{kind=link}
Intel CPU向けについては、公式バージョンで既にある程度のSSE/MMXを用いた最適化が行われていますが、このページで配布しているバージョン3.99ではさらに独自の最適化を加えています (下のグラフを参照)。
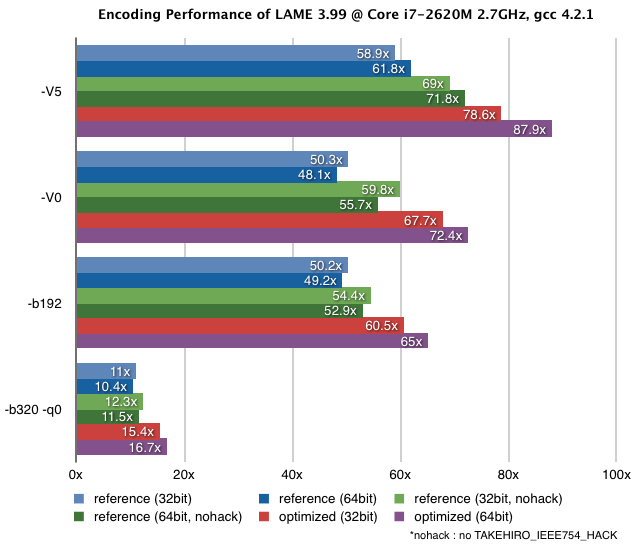
lame 3.100 (2023/4/18更新)
- 実行ファイル for Mac OS X clang(x86/arm64)とgcc 4.2.1(PPC)でコンパイルされたものです。全てのマシン用のユニバーサルバイナリです。最適なものが自動的に選択されます。
- 実行ファイル for Windows gcc 5.4/MinGWでコンパイルされたものです。32bit用と64bit用の両方を含みます。
- ソース差分 (x86)
- 最適化されたコードはgccのインラインアセンブラ向けに書かれているので、gcc (もしくはclang) でコンパイルしてください。
- SSE2のサポートが必要です
- コンパイラでSSE3が有効になっている場合 (-msse3)、SSE3の命令が使われます。
- コンパイラでSSE4.1が有効になっている場合 (-msse4.1)、SSE4.1の命令が使われます。
- 32bit環境では、SSEで浮動小数点演算を行う設定 (-msse2 -mfpmath=sse) を推奨します (Apple製のgccでは標準で有効)。
- ソース差分 (PPC)
- G5向けのバイナリをビルドするには、ALTIVECとALTIVEC_970マクロを定義してください。
- G4向けのバイナリをビルドするには、ALTIVECマクロを定義してください。
- G3向けのバイナリをビルドするには、PPC_FRSQRTEマクロを定義してください。
- ソース差分 (ARM)
- clangもしくはgccでコンパイル可能なことを確認していますが、gccは著しく非効率なコードを生成するため、clangの使用を強くおすすめします。
- AArch64(ARM64)向けの最適化ですが、32bit (ARMv7) 環境でも一応動きます。32bit向けにコンパイルする場合は
-mfpu=neonスイッチを指定してNEONを有効化する必要があります。 - 32bit向けの場合、
-mfpu=neon-vfpv4スイッチを指定することでFMA (Fused Multiply-Add) 命令を使うようになります。
lame 3.99.5 (2012/2/29更新)
- gcc 4.2 バイナリ for Mac OS X gcc 4.2.1でコンパイルされたものです。全てのマシン用のユニバーサルバイナリです。最適なものが自動的に選択されます。なお、Intel 64bit版については最適化の結果32bit版より高速になったので含めるようにしました (オリジナルのLAMEでは、64bit版は32bit版よりもSSEで最適化されている箇所が少ないため、オプションによっては32bit版より遅くなります)。
- gcc 4.6/MinGW バイナリ for Windows 64bit版は動作確認していません。
- ソース差分 (x86)
- 最適化されたコードはgccのインラインアセンブラ向けに書かれているので、gcc (もしくはclang) でコンパイルしてください。
- SSE2のサポートが必要です
- コンパイラでSSE3が有効になっている場合 (-msse3)、SSE3の命令が使われます。
- コンパイラでSSE4.1が有効になっている場合 (-msse4.1)、SSE4.1の命令が使われます。
- 32bit環境では、SSEで浮動小数点演算を行う設定 (-msse2 -mfpmath=sse) を推奨します (Apple製のgccでは標準で有効)。
- Robert Kausch氏の報告により、最近のgccで問題があることが分かり2015/10/3にパッチのみを更新しました。
- ソース差分 (PPC)
- G5向けのバイナリをビルドするには、ALTIVECとALTIVEC_970マクロを定義してください。
- G4向けのバイナリをビルドするには、ALTIVECマクロを定義してください。
- G3向けのバイナリをビルドするには、PPC_FRSQRTEマクロを定義してください。
lame 3.98.4 (2010/3/23更新)
- gcc4.2バイナリ for Mac OS X gcc 4.2.1でコンパイルされたものです。全てのマシン用のユニバーサルバイナリです。最適なものが自動的に選択されます。
- ソース差分
- G5向けのバイナリをビルドするには、ALTIVECとALTIVEC_970マクロを定義してください。
- G4向けのバイナリをビルドするには、ALTIVECマクロを定義してください。
- G3向けのバイナリをビルドするには、PPC_FRSQRTEマクロを定義してください。
このページはリンクフリーです。
一応連絡先